

全球厂商前十!云知声登上LLM Stats 排行榜
欢迎订阅《信阳手机报》移动用户发送短信 XYSJB 到10658300即可开通 3元/月 不收GPRS流量费
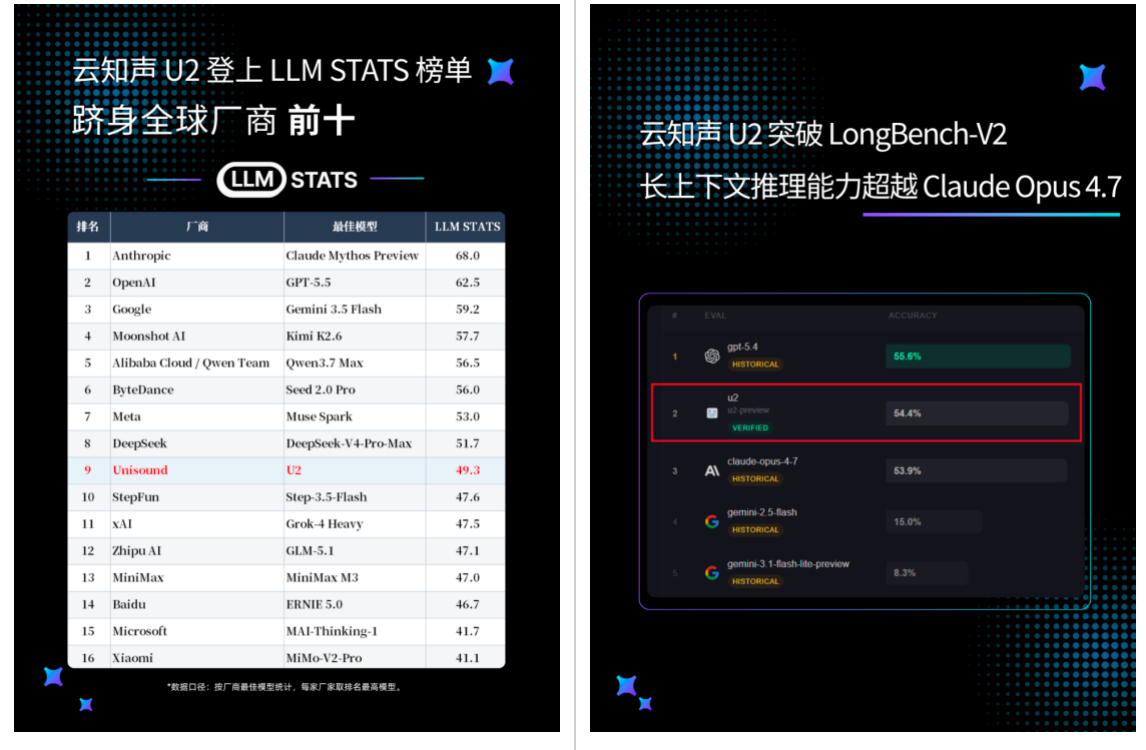
今日,海外权威 AI 模型评测平台 LLM Stats 更新榜单,云知声 U2 登上两项关键评测:在 LLM Stats Score 综合能力榜单中进入模型总榜前 30,按厂商最佳模型成绩位列全球模型厂商第九;同时,在平台收录的独立长上下文评测基准 LongBench-V2 中,U2 以 54.4% 的Accuracy 超越 Claude Opus 4.7。
LLM Stats Score 不是为了刷榜而设计的单一测试集排名,而是面向真实工作负载构建的综合能力评分体系。其综合分数来自公开来源、独立采样测量与经验证的 benchmark 结果。在此基础上,LLM Stats Score 覆盖推理、代码、知识、工具与智能体、长上下文等多个维度,更接近对模型综合战斗力的横向检验。
LongBench-V2 则是当前长上下文推理领域的高难度评测基准之一。该测试集包含 503 道多选题,上下文长度覆盖 8K 至 2M words,并按 short、medium、long 三个长度区间分别评估模型表现,覆盖单文档问答、多文档问答、长上下文学习、长对话历史理解、代码库理解和长结构化数据理解六大类任务,重点检验模型在不同上下文规模下处理长任务的稳定性。
两项评测成绩,正是 U2 在通用能力与复杂任务处理上持续突破的最好证明。
而支撑这一切的,是 U2 “高智能密度 × 高 Token 价值”的核心技术主张:
作为云知声面向真实任务执行打造的原生智能体大模型,U2一方面通过更高效的模型结构和能力承载方式,在更少激活资源下释放更强推理能力;另一方面通过混合思考机制、长上下文理解和任务链路规划能力,让每一次调用、每一个 Token 都更接近有效交付。
接下来,U2 将持续围绕复杂推理、长文本处理、代码生成与 Agent 任务执行等方向优化,不断提升在真实工作流中的交付能力,做更懂任务执行的大模型。
 文章投诉热线:156 0057 2229 文章投诉邮箱:291 3236@qq.com
文章投诉热线:156 0057 2229 文章投诉邮箱:291 3236@qq.com
标签:
- 上一篇:以纤维为界,赴美学之约|「触手可及」纤维艺术大展即将登陆贵阳
- 下一篇:没有了
 报晓风
报晓风 信阳日报微信
信阳日报微信 掌上信阳微信
掌上信阳微信 信阳日报新浪微博
信阳日报新浪微博 信阳日报腾讯微博
信阳日报腾讯微博
请您文明上网、理性发言,并遵守相关规定。网友评论
网友评论仅供其表达个人看法,并不表明信阳新闻网立场。

