

以产品力验证AI自主可控:三大核心产品搭载自研底座模型已面世
欢迎订阅《信阳手机报》移动用户发送短信 XYSJB 到10658300即可开通 3元/月 不收GPRS流量费
当“自主可控”从政策倡导走向产业实践,市场最终需要回答的不是“要不要做”,而是“做得怎么样了”。在这一背景下,国产大模型的产品化落地进展,正在成为检验自主可控成色的关键标尺。
关于国产大模型“自主可控”的叙事,行业并不缺乏。但如果把视角从发布会拉回到日常使用场景,一个更真实的问题浮出水面:市场究竟凭什么相信自主可控的大模型“已经能用了”?
不是凭白皮书,不是凭榜单排名,甚至不完全是凭技术架构。最终,市场信任的锚点只有一个:是否有真实产品,在高要求场景中持续运转,并且用户愿意持续为之买单。
近期,科大讯飞三款搭载全国产算力训练底座模型的产品集中亮相:科大讯飞AI学习机T90系列、讯飞晓医APP、以及讯飞智能座舱交互系统。它们分别进入了教育、医疗、汽车三个对可靠性要求极高的行业,构成了一组颇具说服力的“产品验证链”:不是在讲自主可控“能做什么”,而是在用产品证明它“已经在做、已经在用、已经经得起检验”。
一个前提:底座从何而来
讨论产品之前,有必要先厘清底座的成色。
讯飞星火X2基于全国产算力平台完成训练,采用293B MoE稀疏架构,推理性能较上一代提升50%,通用能力对标国际顶尖水平。据公开信息,讯飞星火迄今仍是唯一在国产算力上完成关键版本训练的主流大模型。
科大讯飞董事长刘庆峰在公司年会上曾给出一组坦率的数字:行业头部企业手握十几万张英伟达卡,讯飞仅靠两三万张国产卡攻坚,算力性能差距达十几倍。资源不对等是客观事实,但也正因如此,星火X2在产品端的实际表现就成了一块更有分量的“试金石”——
如果在算力受限条件下训出的模型仍能驱动高要求场景的产品体验,那么自主可控的可行性就不再只是一种论证,而是一个事实。
以下三款产品,从三个不同维度提供了这一事实的佐证。
科大讯飞AI学习机T90系列:高频使用下的效果闭环
自主可控大模型能不能在C端高频产品中”用出效果”?这个问题的答案不在实验室,而在每天数百万次的真实交互中。
教育场景的苛刻之处在于:它不接受”差不多对”。AI批改一道数学题,不是判断对错就够了,而要定位错在哪一步、错因是什么、该补什么知识点。这是一条从底座推理能力到学科知识图谱再到个性化路径规划的完整链路,任何一环断裂,产品体验都会塌方。
科大讯飞AI学习机T90系列在星火X2底座加持下,实现了业界首创的“错因贯穿”个性化学习闭环。其精准学功能通过“测-学-练”三步走,为每个学生规划专属路径——同样错了勾股定理的题,学优生和学困生的推荐路径完全不同。T90 Pro搭载的超拟人AI老师“晓悦”,则将错因诊断从后台推到了前台交互:先定位错因,再以板书配合启发式讲解回应,学生可随时打断提问。

据科大讯飞教育技术学情与数据平台的数据,同一章节查漏补缺时间减少64%,学会率提升3.1倍。这套方案的校内验证基础覆盖全国5万余所学校、83个因材施教示范区,从校内验证到家庭场景的迁移已形成完整链路。
这组数据的价值在于:它不是模型跑分,而是终端用户在真实使用中产生的效果反馈。当数以万计的学生每天在用、且效果可量化时,底座模型的“能力成色”就被高频使用本身所验证。
讯飞晓医:高风险场景中的专业可信
如果说教育验证的是“好不好用”,医疗验证的则是“敢不敢信”。
医疗是大模型落地门槛最高的场景之一。不是因为技术最难,而是因为容错率最低。一个诊断建议的偏差可能影响患者的就医决策,一次用药推荐的失误可能带来健康风险。因此,医疗场景对大模型的考核标准不只是“能力够不够强”,更是“专业性能不能经受住权威第三方的审视”。
星火医疗大模型在X2底座升级后,在智能健康分析、报告解读、辅助诊疗、用药审核等关键任务上均保持业界领先。而真正具有行业标杆意义的节点是:星火医疗大模型已率先通过上海市医疗大模型应用检测验证中心的评测验证。这一中心由上海人工智能实验室牵头建设,华山医院、中山医院、瑞金医院等12家顶尖三甲机构组成首批验证单位,是国内首个面向医疗大模型的官方评测平台。通过这一评测,本质上意味着模型的专业能力在临床级别的标准下被正式认可。

在产品端,讯飞晓医APP已累计完成超1.8亿次AI健康咨询,覆盖全国800多个区县,满意度达98%。它支持多轮主动问诊、检验单深度解读、精细化慢病管理,并提供“对话不存档、不用于模型训练”的隐私模式。
1.8亿次咨询不是一个抽象数字。它意味着这套基于自主可控底座的医疗AI,已经在真实的、高风险的健康决策场景中被反复使用和检验,且通过了来自用户端和权威机构端的双重信任测试。
讯飞汽车智能座舱交互系统:物理世界约束下的端侧能力
云端场景考验模型的“天花板”,端侧场景考验的则是“地板”。在算力极度受限、实时性要求极高、容错空间极小的物理环境中,底座能力是否还能撑住?
汽车智能座舱恰恰是这样一个场景。有限的车载算力、嘈杂的驾驶环境、用户高度随意的自然语言表达,以及对响应延迟的零容忍,共同构成了对端侧模型的极限压力测试。
基于星火X2的升级,讯飞面向汽车座舱的2B、7B、30B-A3等多尺寸端侧模型同步完成迭代。其中最值得关注的突破在于模糊意图理解:此前评测中该能力处于“完全不可用”状态,此次升级后跃升至“基本好用”水平,智能交互实车评测实现业内全面领先。
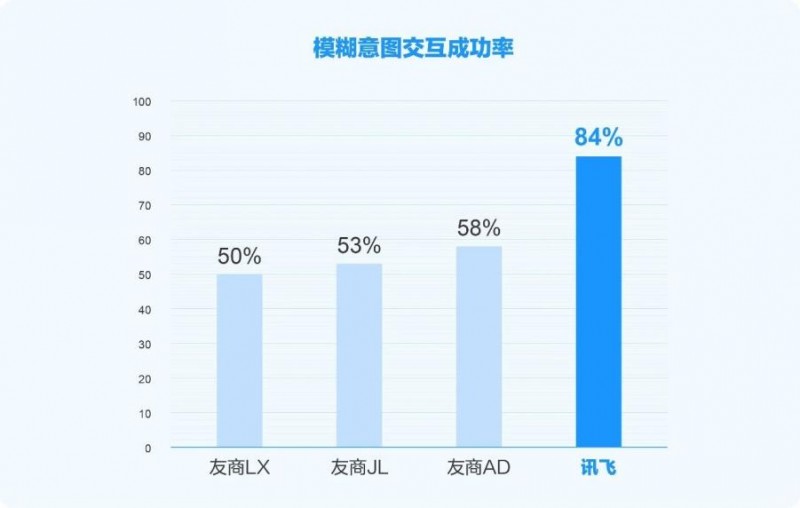
这意味着车机交互正在跨越一个质变节点:从“用户必须说对关键词,系统才能执行”到“用户随便怎么说,系统都能理解意图”。端侧模型能力的这类跃迁,证明的不仅是算法层面的进步,更是自主可控底座在工程化落地上的系统能力。从模型压缩、量化部署到多尺寸适配,每一步都需要在国产硬件平台上重新打通。当这些能力最终转化为用户在方向盘后的自然交互体验时,“自主可控”就从一个供应链概念变成了一个可感知的产品事实。
三条证据指向同一个结论
教育场景提供了“效果验证”:数以万计的学生每天在用,学习效率的提升可量化、可追踪。医疗场景提供了“信任验证”:通过国内最高级别的权威评测,在1.8亿次真实咨询中建立专业可信度。座舱场景提供了“工程验证”:在算力极度受限的端侧物理环境中,实现了交互体验的质变式突破。
三条线索各自独立,但指向同一个结论:基于全国产算力训练的自研底座模型,已经不再停留在“可用”阶段,而是进入了“在高要求场景中持续交付可靠体验”的产品阶段。
这或许也回应了行业一个更深层的疑问。过去谈自主可控,往往聚焦于“卡脖子”的风险叙事;而当产品力成为验证手段,叙事的重心正在从“不得不做”转向“确实做到了”。自主可控的价值,最终不是靠声明来确立,而是靠每天的产品使用来兑现。
据悉,星火X2能力已通过讯飞开放平台面向全球超1000万开发者开放API调用。而对于三款已面世的产品而言,它们每天积累的真实使用数据和用户反馈,本身就是产品力对“国产大模型自主可控”最持续、最有力的验证。
 文章投诉热线:156 0057 2229 文章投诉邮箱:291 3236@qq.com
文章投诉热线:156 0057 2229 文章投诉邮箱:291 3236@qq.com
标签:
- 上一篇:深耕本土链动全球 惠科股份打造中国显示面板出海标杆
- 下一篇:没有了
 报晓风
报晓风 信阳日报微信
信阳日报微信 掌上信阳微信
掌上信阳微信 信阳日报新浪微博
信阳日报新浪微博 信阳日报腾讯微博
信阳日报腾讯微博
请您文明上网、理性发言,并遵守相关规定。网友评论
网友评论仅供其表达个人看法,并不表明信阳新闻网立场。

