

从算法到工程,讯飞星火X1的“技术执念”是打造真正自主可控的AI大模型
欢迎订阅《信阳手机报》移动用户发送短信 XYSJB 到10658300即可开通 3元/月 不收GPRS流量费
文章认可DeepSeek对于中国AI发展的里程碑式意义,却也呼吁市场保持理性,全球AI竞争才刚刚起跑,当下远没到摇旗呐喊的时候。
技术上的跃升过后,更大的战场在于,如何让技术的价值在各行各业最大程度释放。
不可否认,在OpenAI o1和DeepSeek R1的带动下,深度推理模型已然成为大模型落地应用的“必答题”。然而,深度推理模型真正从实验室走向真实场景,仍要面临重重挑战。
具体来看,训练层面,深度推理模型对数据质量要求极高,需要融合结构化知识与海量非结构化数据,但传统强化学习方法存在样本覆盖不均、难度分布失衡问题,导致模型“偏科”;推理层面,MoE架构虽通过稀疏激活专家提升训练效率,但在实际部署中因批量处理能力弱、显存占用高,可能导致延迟陡增。
而在基础设施层面,中美博弈态势越发紧张,美国对华算力管控趋严(如H20芯片禁售),进一步加剧了供应链风险。在此背景下,加速国产替代已是必然。不过,虽然国产算力平台已经快速发展,但在训练大规模深度推理模型时,仍面临适配难度高、集群稳定性不足等挑战。
落实到具体的企业部署环节,大模型私有化部署也有一定算力需求,很多中小企业难以承受。同时,行业场景对模型定制化需求强烈,但现有工具链支持不足,导致定制周期长、成本高。
在此背景下,市场迫切需要全栈自主可控、低成本、高性能的深度推理模型,补齐技术和需求之间的鸿沟。
4月20日,深度推理大模型讯飞星火X1迎来全新升级,给上述疑难杂症提供了一个高效的解法。
作为业界唯一基于全国产算力训练的深度推理大模型,星火 X1在数学、代码、逻辑推理、文本生成、语言理解、知识问答等通用任务效果上显著提升,全面对标OpenAI o1和DeepSeek R1。
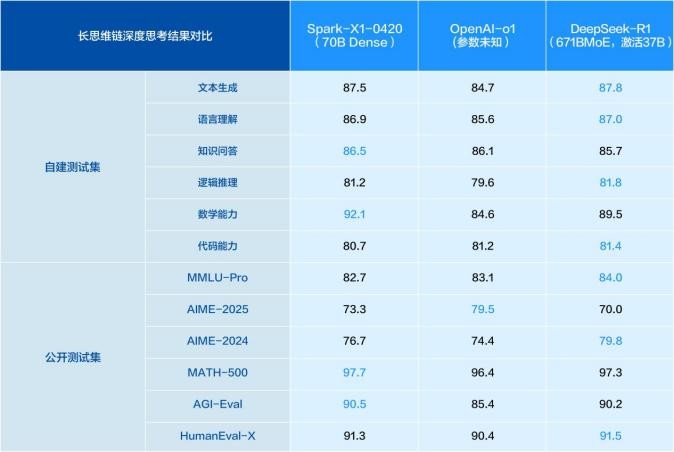
具体来看,星火X1的突出表现来源于三大技术创新:
首先,星火X1引入基于问题复杂度的大规模多阶段强化学习方法,显著提升了模型的泛化能力;同时还开发了一种强化学习动态更新算法,能够根据样本采样的长度灵活调整更新速率,以优化学习效率。
其次,星火X1探索了一种统一模型下的快慢思考混合训练方法,可基于系统指令控制模型是否深度思考,为下游任务提供了更加灵活、高效的部署体验。
在工程技术方面,星火X1也实现了多项创新,例如:采用显存动态卸载技术大幅提升了处理长文本推理时的并发性能;通过训推共卡协同机制实现了训练与推理资源的有效转换;利用推理引擎的冬眠机制实现了快速启动和状态恢复。
这些技术创新共同确保了星火X1在国产计算平台上能够实现高效且稳定的强化学习训练全流程。

具体到部署环节,星火X1还对其模型定制优化工具链进行了全面升级,现在支持SFT(监督微调)和强化学习两种模型定制优化方案。这意味着仅需使用16张华为910B芯片,就能高效完成针对特定行业的定制与优化工作,有效降低了企业AI的定制标准。
更值得一提的是,“满血版”的星火X1系统只需配备4张华为910B芯片即可实现部署,极大地简化了私有化部署的流程,进一步推动了AI普惠的进程。
目前,星火X1已在教育、医疗、司法等领域相继落地应用。

在全栈自主可控方面,科大讯飞与华为昇腾联合团队在前期工作基础上再获突破,升级MoE模型的PD分离+大规模专家并行系统方案,集群推理性能翻番,包括PD分离部署提升20%+性能、MTP多token预测技术提升30%+整体性能、专家负载均衡算法优化使集群吞吐提升30%+,以及异步双发射技术降低服务请求调度耗时提升10%系统性能。
可以看到,从算法创新到完善应用工具链,再到国产基础设施生态建设,科大讯飞已经在国产AI全栈自主可控的方向跑通了自己的模式。
自1999年成立以来,科大讯飞一直坚持“技术顶天,应用立地”的准则,他们技术起家,在语音识别、机器翻译、认知智能等赛道持续深耕,创下多个“首次突破”的纪录。
而此次星火X1的升级,是其在AI核心技术领域拿下的又一个“首次突破”。于中国AI行业而言,这是又一次里程碑式意义的技术跃升;而对于科大讯飞而言,这也是又一次宝贵的自我超越。
 文章投诉热线:156 0057 2229 文章投诉邮箱:291 3236@qq.com
文章投诉热线:156 0057 2229 文章投诉邮箱:291 3236@qq.com
标签:
- 上一篇:AI IPO热潮涌动,特斯联等企业技术出海重构全球产业估值体系
- 下一篇:没有了
 报晓风
报晓风 信阳日报微信
信阳日报微信 掌上信阳微信
掌上信阳微信 信阳日报新浪微博
信阳日报新浪微博 信阳日报腾讯微博
信阳日报腾讯微博
请您文明上网、理性发言,并遵守相关规定。网友评论
网友评论仅供其表达个人看法,并不表明信阳新闻网立场。

